Este guia descreve o procedimento detalhado para recuperar documentos nos formatos DOC, DOCX, XLS, XLSX e PDF usando o Recuva.
Antes de começar, é necessário entender como o Recuva localiza arquivos perdidos. A exclusão de um arquivo no Windows não leva à destruição física imediata dos dados. O sistema operacional apenas marca a área no disco ocupada por esse arquivo como livre para sobrescrita, removendo a referência a ela da tabela mestre de arquivos (MFT) no NTFS ou da tabela de alocação de arquivos no FAT32.
O Recuva usa dois modos principais de verificação: Rápida e Profunda. A verificação rápida analisa a MFT e encontra registros de arquivos excluídos recentemente. A verificação profunda (Deep Scan) usa análise de assinatura, examinando o conteúdo da unidade setor por setor em busca de sequências de bytes características que correspondem ao início (cabeçalho) e ao fim de um arquivo. Para documentos do Word, a assinatura é uma sequência de bytes específica que descreve um contêiner OLE (para formatos mais antigos) ou um arquivo ZIP com estrutura XML (para DOCX/XLSX). Arquivos PDF são identificados pela sequência de bytes %PDF no início do arquivo.
Um fator chave para o sucesso é cessar imediatamente qualquer atividade na partição lógica onde os dados perdidos estavam localizados. Cada operação de gravação, incluindo inicializar o sistema, atualizar o cache do navegador ou instalar o próprio Recuva nessa mesma unidade, pode sobrescrever irreversivelmente os setores que o programa tentará recuperar.
Configurando parâmetros de verificação para documentos de escritório
O Recuva oferece uma interface de assistente e um modo avançado. Para pesquisas direcionadas de documentos Word, Excel ou PDF, o assistente é o método de filtragem mais rápido.
Ao iniciar o assistente, na etapa de seleção do tipo de arquivo ("File Type"), você deve escolher a categoria "Documents". Este filtro é configurado pelo desenvolvedor para exibir apenas arquivos com as seguintes extensões: DOC, DOCX, XLS, XLSX, PPT, PPTX, ODT, ODS, PDF, ODC. Selecionar esta categoria exclui arquivos de multimídia e lixo de sistema dos resultados da verificação, concentrando os recursos computacionais nos formatos alvo.
Na etapa "File Location", você precisa especificar a unidade ou pasta específica onde o arquivo estava localizado antes da perda. Escolher a opção "In a specific location" e especificar manualmente o caminho exato para o diretório, por exemplo D:\Projects\Reports, reduz significativamente a área de análise. Isso não anula uma verificação completa do disco, mas filtra os resultados, facilitando a identificação do arquivo desejado.
Ativando e aplicando a função de verificação profunda
Se a verificação rápida não encontrar o arquivo, você deve ativar o mecanismo de verificação profunda (Deep Scan). Isso é especialmente relevante para arquivos PDF e documentos excluídos após a formatação da unidade. A verificação profunda ignora o sistema de arquivos e acessa diretamente os setores da unidade.
Você deve marcar a caixa de seleção "Enable Deep Scan". No modo avançado, esta opção é ativada através do menu de configurações: guia "Actions", onde você precisa marcar "Scan for non-deleted files" e "Enable Deep Scan". Você também pode forçar o modo de verificação usando o botão "Scan Mode" no painel da interface.
Este processo pode levar de várias dezenas de minutos a várias horas, dependendo da capacidade e velocidade da unidade. O Recuva verificará setor por setor, procurando por assinaturas PDF, DOC e XLS. Arquivos encontrados dessa maneira geralmente perdem seus nomes originais e aparecem com nomes técnicos como [001].docx ou file001.pdf, porque o registro do nome na MFT foi perdido.
Interpretando resultados e critérios de avaliação de integridade
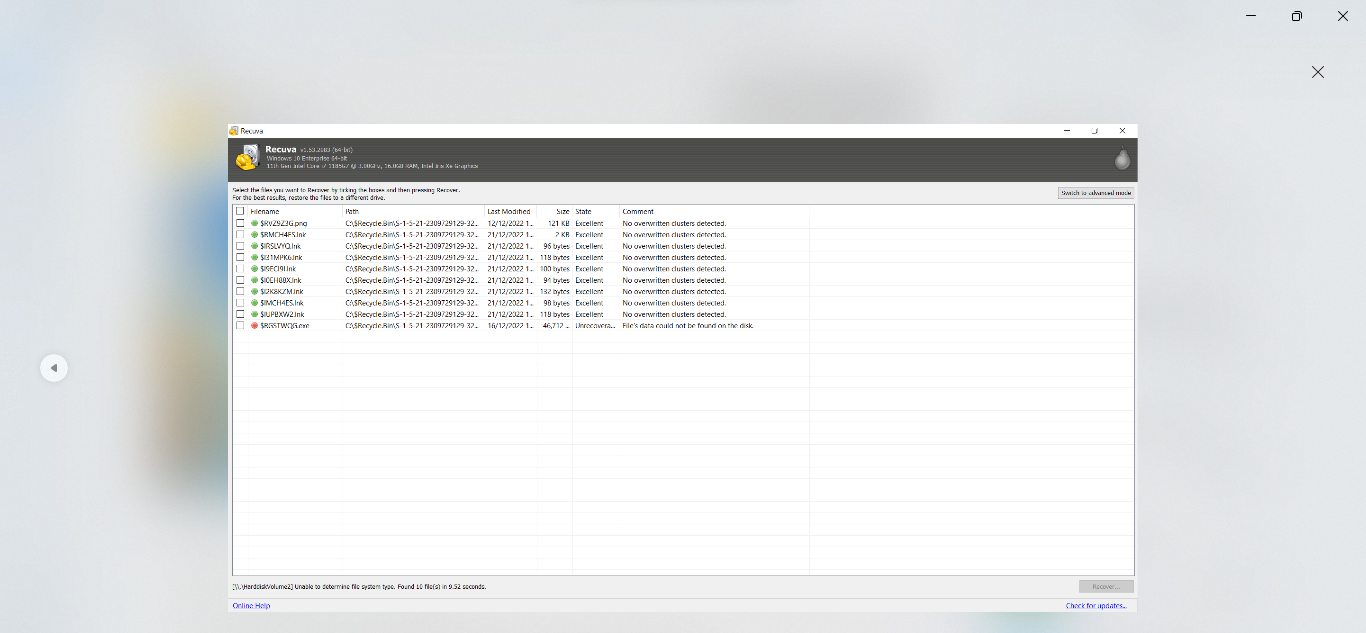
Após a conclusão da verificação, o Recuva exibe uma lista de objetos encontrados. Cada arquivo é acompanhado por um indicador de status colorido:
Marcador verde: O arquivo não foi sobrescrito, seus clusters estão intactos e a probabilidade de recuperação bem-sucedida é próxima de 100%.
Marcador amarelo: Indica sobrescrita parcial ou dano a alguns setores de dados. O documento pode ser recuperável, mas seu conteúdo pode conter caracteres incorretos ou não abrir no aplicativo de destino.
Marcador vermelho: Todos os clusters anteriormente ocupados pelo arquivo foram sobrescritos por outros dados. A recuperação na forma original é impossível.
Preste atenção à coluna "Path" (Caminho) nos resultados da verificação. Para arquivos detectados através da análise profunda de assinatura, o caminho pode ser listado como "unknown" ou denotado por um ponto de interrogação. Para verificar tais arquivos, use a função de visualização integrada no modo avançado; no entanto, ela nem sempre pode exibir corretamente elementos de formatação complexos de arquivos PDF ou DOCX.
Procedimento de recuperação segura
O estágio mais crítico para a segurança dos dados é escolher a localização para os arquivos recuperados. A regra de ouro: nunca salve arquivos recuperados na mesma partição lógica da qual você está recuperando.
Quando o Recuva solicitar um caminho para salvar (diálogo "Browse For Folder"), você deve especificar uma pasta localizada em uma unidade fisicamente diferente. Por exemplo, se estiver recuperando dados da unidade D:, salve-os em uma unidade USB externa, pen drive ou unidade E:. Violar este princípio pode fazer com que o Recuva, durante o processo de salvamento, grave dados exatamente sobre aqueles setores livres onde ainda residem restos dos arquivos recuperáveis, levando à sua corrupção irreversível.
Após selecionar os arquivos na lista e clicar no botão "Recover" (Recuperar), o programa exibirá um relatório estatístico com o número de objetos extraídos com sucesso. Se um arquivo do Word ou Excel estiver corrompido, tente usar as ferramentas de reparo integradas aos pacotes de escritório (a função "Abrir e reparar" no Microsoft Word).
Ações em caso de resultado negativo
Se o Recuva não encontrar vestígios de um documento PDF excluído, o motivo pode ser o seguinte: a unidade é um SSD com o comando TRIM ativo, que zera as células de memória após a exclusão de um arquivo. Pesquisas mostram que o Recuva não consegue recuperar dados excluídos de um SSD onde o comando TRIM foi executado, pois as células físicas são zeradas em nível de hardware. Neste cenário, a recuperação por métodos de software é impossível.
Considere também que software antivírus, indexação ou sincronização em nuvem podem ter sobrescrito os dados antes mesmo de você executar o utilitário. A única medida preventiva para o futuro é o backup regular de documentos criticamente importantes e a ativação da Cópia Sombra de Volume (Volume Shadow Copy) nas configurações do Windows.